
По данным независимого российского бенчмарка MERA Авито обогнал OpenAI и Google.

 Для чего используют VPS: 9 популярных задач виртуального сервера
Для чего используют VPS: 9 популярных задач виртуального сервера На ярославском заводе провели «зеленый субботник»
На ярославском заводе провели «зеленый субботник» Развитие TELEGRAM-канала: стратегия контента и вовлечение
Развитие TELEGRAM-канала: стратегия контента и вовлечение Эксперты рассказали, какие повседневные привычки продлевают жизнь смартфонов и домашней электроники
Эксперты рассказали, какие повседневные привычки продлевают жизнь смартфонов и домашней электроники В Ярославле открылся первый заводской фонтан
В Ярославле открылся первый заводской фонтанПо данным независимого российского бенчмарка MERA Авито обогнал OpenAI и Google.

Большая языковая модель A-Vibe от Авито заняла первое место среди облегченных моделей (до 10 млрд параметров), обойдя международные аналоги GPT-4o mini, Gemma 3 27B, Claude 3.5 Haiku, Mistral Large и другие небольшие нейросети. Тестирование включало задачи различной сложности — от базового понимания текста до продвинутых лингвистических задач, требующих глубокой работы с контекстом. Чтобы попасть в рейтинг, в фильтре «Размер модели» выберите «≥5B — 10B». Это значит, что в рейтинг попадут модели размером от 5 до 10 миллиардов параметров.
Как отмечает бенчмарк MERA, A-Vibe лучше аналогичных моделей понимает запросы, генерирует код и поддерживает осмысленный диалог. Технология помогает продавцам в Авито писать продающие описания и быстрее договариваться о сделке в мессенджере. До конца года компания планирует добавить ещё 20 новых сценариев, а в будущем может открыть код модели для всех. 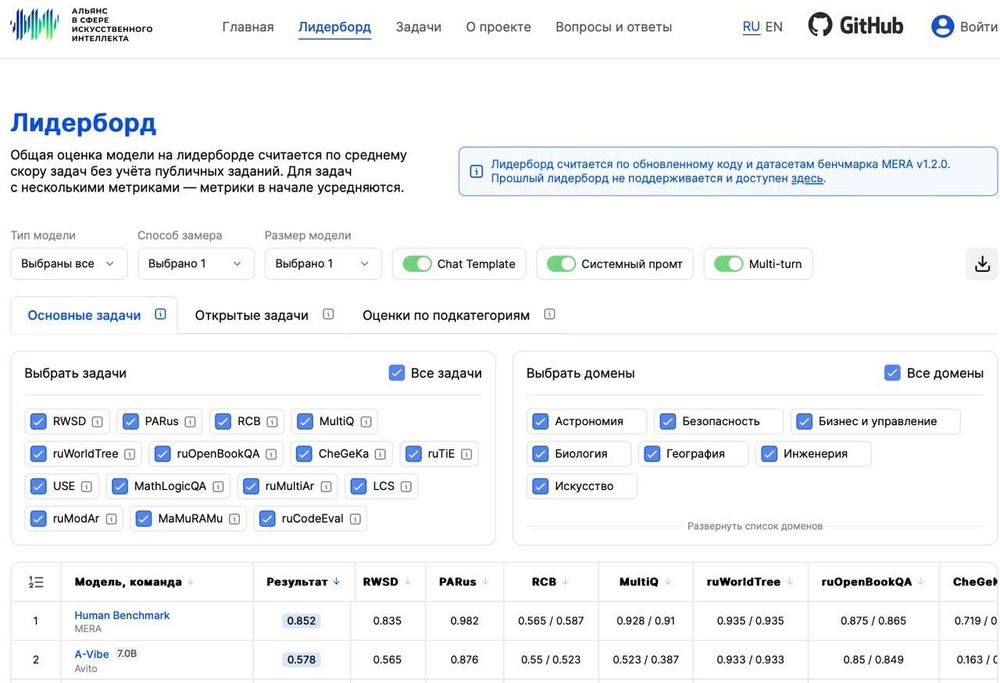
«A-Vibe создавалось оптимальной по соотношению между качеством, скоростью работы и затратой ресурсов. Такой баланс позволяет обеспечивать быструю обработку запросов даже в периоды пиковой нагрузки и масштабировать технологию на всю аудиторию платформы. Именно обучение небольшой модели под наши нужды позволяет нам закладывать окупаемость инвестиций: Авито планирует вложить в GenAI около 12 млрд рублей, а заработать более 21 млрд рублей к 2028 году», – заявил старший директор по данным и аналитике Авито Андрей Рыбинцев.
Команда Авито разработала собственные генеративные модели A-Vibe и A-Vision, использовав для обучения на начальном этапе открытую модель. Она обучалась на данных более чем 100 языков, при этом русский составлял менее 1% общего объема данных. Из-за этого модель плохо понимала и генерировала текст на русском. Разработчики модифицировали и провели «русификацию» модели, заменив стандартный токенизатор на собственный, который умеет работать с русским языком. Это привело к ускорению работы: теперь текст обрабатывается быстрее до 2х раз по сравнению с оригинальной моделью, выросло понимание и генерация текста. При этом A-Vibe может одновременно обрабатывать до 32 тысяч текстовых фрагментов (токенов).
«Мы рассматриваем возможность выпуска модели в открытый доступ, что станет нашим вкладом в развитие российского рынка ИИ. Это поможет малому бизнесу внедрять передовые технологии без значительных инвестиций, образовательным учреждениям создавать прикладные программы, а независимым разработчикам строить современные сервисы на базе отечественных технологий. Для нас это возможность получить ценную обратную связь от рынка и улучшить наши модели», — заявила руководитель разработки больших языковых моделей «Авито» Анастасия Рысьмятова.
Отметим, что цифры HUMAN BENCHMARK — это реальные результаты людей. Языковые модели приближаются к этим значениям, но окончательно превзойти человека ещё не смогли.

Фото происшествия появились в ярославских пабликах.
31.05.2026 в 16:13
Буренки распоясались и губят урожай.
31.05.2026 в 14:09
В обзоре корреспондента ЯрНьюс.
31.05.2026 в 12:01
И потерял на этом почти 400 тысяч рублей.
31.05.2026 в 10:13
14-летнюю девочку госпитализировали.
31.05.2026 в 00:20

В этом году она стартовала в День города столицы «Золотого кольца».
30.05.2026 в 22:02
О продлении контрактов сообщает пресс-служба КХЛ.
30.05.2026 в 18:59

И восстановления благоустройства.
30.05.2026 в 14:09
Он забрал у 81-летней ярославны 1,2 миллиона рублей.
30.05.2026 в 13:16
Ярославская область в спорте держится не на одном только «Локомотиве», хотя он давно стал не просто клубом, а городской системой координат: по команде сверяют настроение сезона, тему для разговоров в офисе и уровень надежды на весну.
30.05.2026 в 13:01
Администрация настаивает на возбуждении уголовного дела.
30.05.2026 в 12:31
Программа разработана Технопарком «Сколково» при участии Авито и ведущего китайского университета.
30.05.2026 в 12:15
Возбуждено уголовное дело.
30.05.2026 в 11:19
У «Локомотива» после Кубка Гагарина появилась красивая вывеска, но главная история не в ней.
30.05.2026 в 10:33
Опубликовано расписание дополнительных рейсов.
30.05.2026 в 10:29
Уголовное дело возбуждено по статье о причинении смерти по неосторожности.
30.05.2026 в 09:51
Обсуждение состоялось в рамках первой отраслевой конференции, посвященной вопросам регулирования цифровых платформ - «ПлатФорум 2026».
30.05.2026 в 09:01
Столица «Золотого кольца» сегодня отмечает 1016-ый день рождения.
30.05.2026 в 07:01
Об этом сообщает региональное СУ СКР.
29.05.2026 в 17:29
Максим Березкин решил пойти за третьим Кубком Гагарина вместе с командой.
29.05.2026 в 17:02
Также его лишили прав на 2 года.
29.05.2026 в 16:50
Жители неоднократно жаловались на жару в салонах.
29.05.2026 в 16:32
Губернатор Ярославской области Михаил Евраев отметил, что системная работа в этом направлении уже приносит результаты.
29.05.2026 в 16:07
Банк Уралсиб запустил программу автокредитования на покупку автомобиля с пробегом у физлиц на Авито.
29.05.2026 в 15:48
Рынок автомобилей с пробегом является одним из крупнейших сегментов авторынка.
29.05.2026 в 15:03
Также с него требуют компенсацию морального вреда.
29.05.2026 в 14:45
Как роутеры работают с сигналом от сети и насколько эффективно раздают интернет проверяли эксперты лаборатории МегаФона.
29.05.2026 в 14:36
 Мешок пригодится: ярославцев наказали на миллион за выброс мусора вне контейнеров
Мешок пригодится: ярославцев наказали на миллион за выброс мусора вне контейнеровВидео одного из правонарушений опубликовал зампред муниципалитета Олег Ненилин.
 В Ярославле освобожден тусовщик, врезавшийся в инспектора ГИБДД
В Ярославле освобожден тусовщик, врезавшийся в инспектора ГИБДДХотя приговор суда был обвинительным.
 В ярославском министерстве прокомментировали видео с гуляющим кабаном
В ярославском министерстве прокомментировали видео с гуляющим кабаномВ ведомстве не уверены, что животное дикое.
 В Ярославле вандалы-граффитчики залезли на крышу цирка
В Ярославле вандалы-граффитчики залезли на крышу циркаЧтобы оставить свои надписи на глазах у изумленной публики.
 ГАИ публикует видео, как ярославский байкер въехал в «Весту»
ГАИ публикует видео, как ярославский байкер въехал в «Весту»Несовершеннолетнему мотоциклисту понадобилась госпитализация.
 Ярославского кота освободили из батарейного плена
Ярославского кота освободили из батарейного пленаПомогли спасатели из «Центра гражданской защиты» Ярославля.
 В тройном ДТП под Ярославлем погибли два водителя и пассажир
В тройном ДТП под Ярославлем погибли два водителя и пассажирВ ГИБДД назвали предварительную причину аварии.
 Видео ограбления бабушки в Ярославле дошло до МВД
Видео ограбления бабушки в Ярославле дошло до МВДОфициальный представитель министерства Ирина Волк заявила, что совершившая преступление фигурантка установлена.
 Ярославль празднует юбилейный день города
Ярославль празднует юбилейный день городаПортал ЯрНьюс предлагает вам небольшой фоторепортаж с праздника.
 Великан Федор и кафетерий-телепорт: ярославец прогулялся по Минску и Витебску
Великан Федор и кафетерий-телепорт: ярославец прогулялся по Минску и ВитебскуКорреспондент ЯрНьюс недавно побывал в соседней стране и делится впечатлениями специально для тех, кто собирается туда поехать.
 В Ярославле переносят ремонт проспекта Машиностроителей: фоторепортаж
В Ярославле переносят ремонт проспекта Машиностроителей: фоторепортажВ 2024 году его доделать нереально — как сейчас идет ремонт дороги увидел и сфотографировал корреспондент ЯрНьюс.
 В Ярославле начался снос Заволжского рынка
В Ярославле начался снос Заволжского рынкаПо словам рабочих в течение месяца от здания ничего не останется.
 Над Ярославской областью зависли облака в виде летающих тарелок
Над Ярославской областью зависли облака в виде летающих тарелокНеобычное явление вечером можно было наблюдать по всему региону.
 В Ярославле высыхает Юбилейный парк
В Ярославле высыхает Юбилейный паркЯрНьюс публикует фоторепортаж с территории, которую можно считать «зелеными легкими» в центральной части города.













